데이터 프레임 이해하기
열은 속성을 나타낸다.
행은 한 사람의 정보를 나타낸다.
한 명에 대한 데이터는 가로 한 줄에 나타난다.
데이터가 크다는 것은 행이 많거나 열이 많다는 것이다.
- 행이 많을 경우 컴퓨터가 느려진다.
- 열이 많을 경우 분석 방법의 한계를 갖는다. (여러 변수의 영향을 고려하기 어려워진다.)
데이터 분석의 가치는 어떤 현상이 조건에 따라 달라진다는 사실을 발견할 때 생겨난다.
ex) 특정 날씨에 어떤 음식이 더 많이 팔린다.
ex) 어떤 모양의 돌에서 교통사고가 많이 발생한다.
| 영어점수 | 수학점수 |
| 90 | 50 |
| 80 | 60 |
| 60 | 100 |
| 70 | 20 |
다음과 같은 데이터 프레임을 만들어보겠다.
우선 학생 네명의 영어점수와 수학점수를 담은 변수를 각각 만든다.
combine()함수를 이용한다.
english <- c(90, 80, 60, 70)
math <- c(50, 60, 100, 20)
english
math

데이터 프레임을 만들때는 data.frame() 함수를 이용한다.
데이터 프레임 변수인 df_midterm을 만들어 english와 math를 할당하겠다.
df_midterm <- data.frame(english, math)
df_midterm
각 변수가 각 열(속성)으로 들어간 것을 알 수 있다.
이번에는 학생의 반에 대한 정보가 추가된 데이터 프레임을 만들어보겠다.
class <- c(1, 1, 2, 2)
class
df_midterm <- data.frame(english, math, class)
df_midterm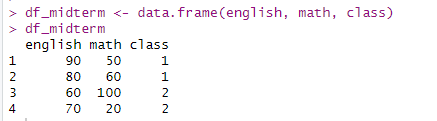
데이터 프레임이 완성되었으니 이를 분석할 수 있다.
mean() 함수를 이용해 전체 학생의 영어점수와 수학점수 평균을 구해보겠다.
df_midterm <- data.frame(english, math, class)
df_midterm
mean(df_midterm$english) #df_midterm의 english속성으로 평균 산출
mean(df_midterm$math) #df_midterm의 math속성으로 평균 산출
기호 $는 dataframe안에 포함되어 있는 열속성(변수)를 가르킨다.
데이터 프레임을 한번에 만드는 방법을 배워보겠다.
df_midterm <- data.frame(english = c(90, 80, 60, 70),
math = c(50, 60, 100, 20),
class = c(1, 1, 2, 2))
df_midterm
04-3 외부 데이터 이용하기
예제로 쓰이는 파일
https://github.com/youngwoos/Doit_R/blob/master/Data/excel_exam.xlsx
Doit_R/Data/excel_exam.xlsx at master · youngwoos/Doit_R
<Do it! 쉽게 배우는 R 데이터 분석> 저장소. Contribute to youngwoos/Doit_R development by creating an account on GitHub.
github.com
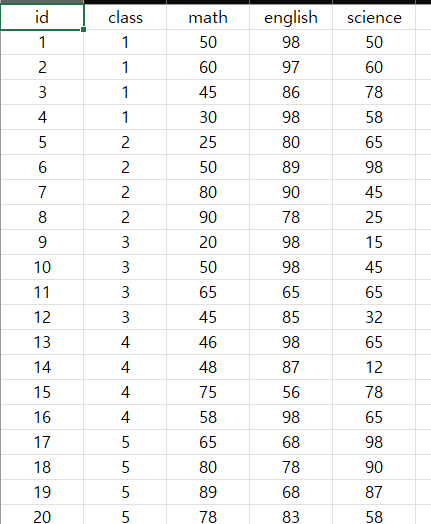
5개의 속성을 담은 5개의 변수가 있음을 알 수 있다.
데이터 파일을 불러오기 위해서는 현재 작업중인 프로젝트 폴더에 xlsx파일을 삽입하는 것이다.
install.packages("readxl")
library(readxl)
readxl 패키지를 설치한 후 실행시켜 준다. packages 창에서 활성화 된 것을 확인해준다.
df_exam <- read_excel("excel_exam.xlsx")
df_exam
read_excel 함수를 이용해 데이터프레임 변수 df_exam에 할당해준다.
프로젝터 폴더 외에 엑셀파일이 위치할 때는 d:/esay_r 처럼 경로를 지정해준다.
파일 앞뒤로 " " 를 찍어주어야 한다.

read_excel 함수는 엑셀파일의 첫번째 행의 값을 변수명으로 인식한다.
이 경우 col_names = F 파라미터를 설정하면 첫번째 행의 값 역시 데이터로 인식하고
변수 명은 숫자를 임의로 할당한다.
df_exam <- read_excel("excel_exam.xlsx", col_names = F)
df_exam
엑셀 파일에 여러개의 시트가 있다면 sheet 파라미터를 이용해 몇번 째 시트를 불러올지 구할 수 있다.
df_exam <- read_excel("excel_exam.xlsx", sheet = 3)
df_exam
.xlsx파일을 데이터프레임으로 불러오기 위해서는 read_excel 함수와 readxl 라이브러리가 필요하다.
.csv파일을 불러오기 위해서는 R내장 함수인 read_excel() 함수를 이용하면 된다.
이때 col_names = F 파라미터와 같은 기능으로 header = F 파라미터를 써야 한다.
데이터 프레임을 CSV 파일로 저장할 수 있다.
write.csv() 함수를 이용하면 된다.
write.csv(df_midterm, file = "df_midterm.csv")
csv 대신 R 전용 데이터 파일은 RDS파일로 저장할 수도 있다.
이때 저장은 saveRDS(), 불러오기는 readRDS() 함수를 이용한다.
rm() 함수는 변수내의 값을 제거할 수 있다.
saveRDS(df_midterm, file = "df_midterm.rds")
rm(df_midterm)
df_midterm <- readRDS("df_midterm.rds")
df_midterm
정상적으로 데이터가 출력된 걸 알 수 있다.
자주 이용하는 파일은 3가지. .xlsx. csv. .rds이다.
'📊 R & 데이터 분석' 카테고리의 다른 글
| 데이터 분석을 위한 R수업 <3차시 ④: 파생변수 만들기> (4) | 2024.10.05 |
|---|---|
| 데이터 분석을 위한 R수업 <3차시 ③: 변수명 바꾸기> (1) | 2024.10.05 |
| 데이터 분석을 위한 R수업 <3차시 ②: 데이터 다루기> (1) | 2024.10.05 |
| 데이터 분석을 위한 R수업 <2차시 : 변수> (1) | 2024.10.03 |
| 데이터 분석을 위한 R수업 <1차시 : ggplot2> (7) | 2024.10.03 |