데이터 분석을 위한 R수업 <4차시 ①: dplyr 활용>
06-1 데이터 전처리 - 원하는 형태로 데이터 가공하기
06-2 조건에 맞는 데이터만 추출하기
06-3 필요한 변수만 추출하기
06-4 순서대로 정렬하기
06-5 파생변수 추가하기
06-6 집단별로 요약하기
06-7 데이터 합치기
06-1 데이터 전처리 - 원하는 형태로 데이터 가공하기
dplyr은 데이터 전처리에 가장 많이 사용되는 패키지 입니다.
dplyr 함수
filter() 행 추출
select() 열(변수) 추출
arrange() 정렬
mutate() 변수추가
summarise() 통계치 산출
group_by() 집단별로 나누기
left_join() 데이터 합치기(열)
bind_rows() 데이터 합치기(행)
06-2 조건에 맞는 데이터만 추출하기
library(dplyr)
exam <- read.csv("csv_exam.csv")
exam

csv.exam.csv를 read.csv 함수로 불러와 exam 변수에 넣었습니다.
여기서 1반 학생들의 데이터만 추출하겠습니다.
exam %>% filter(class == 1)
dplyr 패키지는 %>%를 이용하여 함수를 나열합니다.

2반 학생만 추출해보겠습니다.
exam %>% filter(class == 2)
!=를 이용해서 1반이 아닌 경우를 추출
exam %>% filter(class != 1)
수학점수가 50점 이상인 학생을 추출
exam %>% filter(math > 50)
영어점수가 80점 미만인 학생을 추출
exam %>% filter(english < 80)
여러 조건을 동시에 충족하는 행 추출하기
1반이면서 수학 점수가 50점 이상인 경우 추출
exam %>% filter(class == 1 & math >= 50)
2반이면서 영어 점수가 80점 이하인 경우 추출
exam %>% filter(class == 2 & english <= 80)
여러 조건 중 하나 이상 충족하는 행 추출하기
OR 연산자 | 를 이용하면 된다.
수학 점수가 90점 이상이거나 영어 점수가 90점 이상인 경우
exam %>% filter(math >= 90 | english >= 90)
영어 점수가 90점 미만이거나 과학 점수가 50점 미만인 경우
exam %>% filter(english < 90 | science < 50)
조건 목록에 맞는지 확인하는 %in% 연산자와 c() 함수를 이용해 조건 목록을 제시할 수 있다.
exam %>% filter(class %in% c(1,3,5))
추출한 행으로 새로운 데이터 만들기
class1 <- exam %>% filter(class == 1)
class2 <- exam %>% filter(class == 2)
class1의 math열의 평균 값 보기
mean(class1$math)
06-3 필요한 변수만 추출하기
select() 함수는 데이터의 변수(열)중 추출하고 싶은 변수만을 추출하는데 쓰인다.
exam |> select(math)
%>% 대신 파이프를 사용하였다.
exam |> select(english)
여러 변수를 동시에 추출할 수 있다.
exam |> select(class, math, english)
특정 변수를 제외하고 나머지를 출력할 수도 있다.
exam |> select(-math)
filter()와 select() 조합하기
exam |> filter(class == 1) |> select(english)
1반 학생들을 찾아서 english 변수만 보여주는 함수
단락을 나눠서 아래처럼 표현할 수도 있다.
exam |>
filter(class == 1) |>
select(english)
exam |>
select(id, math) |>
head(6)
06-4 순서대로 정렬하기
arrange() 함수를 이용하면 데이터를 원하는 순서로 정렬할 수 있습니다.
math에 대해 오름차순 정렬
exam |> arrange(math)
> exam |> arrange(math)
id class math english science
1 9 3 20 98 15
2 5 2 25 80 65
3 4 1 30 98 58
4 3 1 45 86 78
5 12 3 45 85 32
6 13 4 46 98 65
7 14 4 48 87 12
8 1 1 50 98 50
9 6 2 50 89 98
10 10 3 50 98 45
11 16 4 58 98 65
12 2 1 60 97 60
13 11 3 65 65 65
14 17 5 65 68 98
15 15 4 75 56 78
16 20 5 78 83 58
17 7 2 80 90 45
18 18 5 80 78 90
19 19 5 89 68 87
20 8 2 90 78 25
math에 대해 내림차순 정렬
exam |> arrange(desc(math))
desc()를 넣어주면 된다.
> exam |> arrange(desc(math))
id class math english science
1 8 2 90 78 25
2 19 5 89 68 87
3 7 2 80 90 45
4 18 5 80 78 90
5 20 5 78 83 58
6 15 4 75 56 78
7 11 3 65 65 65
8 17 5 65 68 98
9 2 1 60 97 60
10 16 4 58 98 65
11 1 1 50 98 50
12 6 2 50 89 98
13 10 3 50 98 45
14 14 4 48 87 12
15 13 4 46 98 65
16 3 1 45 86 78
17 12 3 45 85 32
18 4 1 30 98 58
19 5 2 25 80 65
20 9 3 20 98 15
정렬 기준으로 삼을 변수를 여러개 지정할 수 있다.
exam |> arrange(class, math)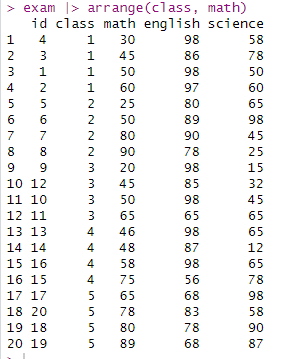
06-5 파생변수 추가하기
mutate() 함수를 이용하면 파생변수를 만들어 추가할 수 있다.
exam |>
mutate(total = math + english + science) |>
head()
> exam |>
+ mutate(total = math + english + science) |>
+ head()
id class math english science total
1 1 1 50 98 50 198
2 2 1 60 97 60 217
3 3 1 45 86 78 209
4 4 1 30 98 58 186
5 5 2 25 80 65 170
6 6 2 50 89 98 237
여러 파생변수 한번에 추가하기위해서는 ,를 이용하면 된다.
exam |>
mutate(total = math + english + science,
mean = total/3) |>
head()
> exam |>
+ mutate(total = math + english + science,
+ mean = total/3) |>
+ head()
id class math english science total mean
1 1 1 50 98 50 198 66.00000
2 2 1 60 97 60 217 72.33333
3 3 1 45 86 78 209 69.66667
4 4 1 30 98 58 186 62.00000
5 5 2 25 80 65 170 56.66667
6 6 2 50 89 98 237 79.00000
mutate()에 ifelse()를 적용하면 조건에 따라 다른 값을 부여한 변수를 추가할 수 있다.
exam |>
mutate(test = ifelse(science >= 60, "pass", "fail")) |>
head()
mutate()와 arrange()의 조합
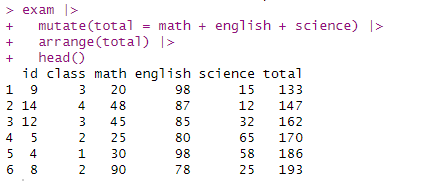
exam |>
mutate(total = math + english + science) |>
arrange(total) |>
head()
★dplyr 함수에는 데이터 프레임명을 반복하여 입력하지 않기 때문에 코드가 간결해진다.
06-6 집단별로 요약하기
집단별 평균이나 집단별 빈도처럼 각 집단을 요약한 값을 구할 때는
group_by()와 summarise() 함수를 이용한다.
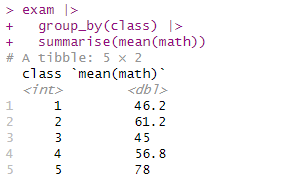
exam |>
summarise(mean_math = mean(math))
math 변수의 평균을 구해서 mean_math에 넣고 출력한다.
집단별로 요약하기
exam |>
group_by(class) |>
summarise(mean_math = mean(math))
group_by()에 변수를 저장하면 변수 항목별로 데이터를 분리한다.
여기에 summarise를 조합하면 집단별 요약 통계량을 만든다.
여러 요약 통계량 한번에 산출하기
exam |>
group_by(class) |>
summarise(mean_math = mean(math),
sum_math = sum(math),
median_math = median(math),
n = n())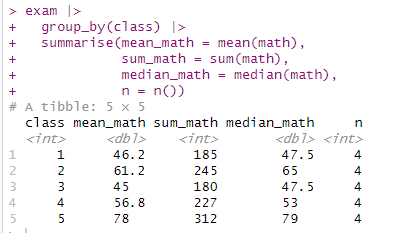
각 집단별로 다시 집단나누기
mpg |>
group_by(manufacturer, drv) |>
summarise(mean_cty = mean(cty)) |>
head(10)
manufacturer로 나눈 집단을 다시 drv로 나누어 보기
그리고 그 나눠진 집단에서 cty의 평균 보기

하나의 dplyr 구문 만들기
mpg |>
group_by(manufacturer) |> #회사별로 분리
filter(class == "suv") |> #suv 추출
mutate(tot = (cty+hwy)/2) |> #통합연비 변수 생성
summarise(mean_tot = mean(tot)) |> #통합 연비 평균 산출
arrange(desc(mean_tot)) |> #내림차순 정렬
head(5) # 1위부터 5위까지 출력# A tibble: 5 × 2
manufacturer mean_tot
<chr> <dbl>
1 subaru 21.9
2 toyota 16.3
3 nissan 15.9
4 mercury 15.6
5 jeep 15.6'📊 R & 데이터 분석' 카테고리의 다른 글
| 나스닥과 S&P 500 추종 ETF 비교 (QQQ VS SPLG) (10) | 2024.11.08 |
|---|---|
| 데이터 분석을 위한 R수업 <4차시 ②: 데이터 합치기> (3) | 2024.10.19 |
| 2024 변호사 시험 기수별 응시자 · 합격자 정보 (4) | 2024.10.10 |
| 데이터 분석을 위한 R수업 <3차시 ④: 파생변수 만들기> (4) | 2024.10.05 |
| 데이터 분석을 위한 R수업 <3차시 ③: 변수명 바꾸기> (1) | 2024.10.05 |