반응형
DeepSeek-R1 모델 소개
- DeepSeek-R1의 배경
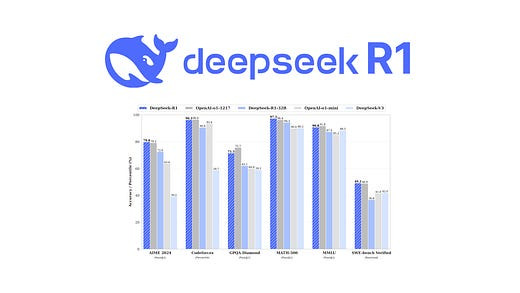
DeepSeek-R1은 복잡한 문제 해결(수학, 코딩, 논리 등)에서 뛰어난 성능을 보이는 reasoning 모델입니다. OpenAI의 o1 모델처럼, 모델이 추론 능력을 향상시키기 위해 추론 과정에 집중하는 방식이 도입되었습니다. - 모델의 핵심 혁신
- 기본 모델 활용: DeepSeek-R1은 강력한 기본 모델(DeepSeek-V3, 671B Mixture of Experts)을 기반으로 합니다.
- 비용 효율성: Multi Token Prediction(MTP), Multi-Head Latent Attention(MLA)와 같은 아키텍처 변경과 하드웨어 최적화를 통해 훈련 비용을 약 550만 달러로 낮췄습니다.
- 두 가지 모델 접근법:
- DeepSeek-R1-Zero: 감독 학습 없이 순수 강화학습(RL)만 사용하여 그룹 상대 정책 최적화(GRPO) 기법으로 모델을 훈련. 문제를 단계별로 분해하고 자체 검증하는 추론 능력을 개발했으나, 응답의 명료성이 부족한 경향이 있음.
- DeepSeek-R1: 소규모의 세심하게 구성된 예제 데이터로 '콜드 스타트' 단계를 거쳐 모델의 응답 명료도와 일관성을 개선한 후, 추가 RL과 정제 단계를 통해 높은 품질의 출력을 생성함.

DeepSeek-R1의 미흡한 부분과 Open-R1 프로젝트의 등장
- 미공개 자료:
DeepSeek-R1은 모델 가중치는 공개했지만, 훈련에 사용된 데이터셋과 코드 등 핵심 자료는 공개하지 않아 재현 연구에 한계가 있었습니다. - Open-R1 프로젝트의 목표:
DeepSeek-R1의 데이터 및 훈련 파이프라인을 재현하고 검증함으로써, 강화학습이 추론 능력 향상에 어떻게 기여하는지 투명하게 공개하는 것을 목표로 합니다. 이를 통해 연구 및 산업 커뮤니티가 유사하거나 더 나은 모델을 개발할 수 있도록 기반을 마련하고자 합니다. - 프로젝트의 구체적 계획:
- R1-Distill 모델 복제: DeepSeek-R1에서 고품질 추론 데이터셋을 증류(distill)하여 복제.
- 순수 RL 파이프라인 복제: DeepSeek-R1-Zero 방식처럼 수학, 추론, 코드 등 대규모 데이터셋을 새롭게 구성하여 순수 강화학습 방법론을 재현.
- 다단계 훈련 과정 시연: 기본 모델에서 감독 학습(SFT)을 거쳐 강화학습(RL)까지 이어지는 다단계 훈련 과정을 증명.
- 확장 가능성 및 커뮤니티 참여:
- 추론뿐만 아니라 코드, 의료 등 다른 분야로의 확장이 가능하며, 오픈 소스 커뮤니티의 참여를 통해 지속적으로 개선될 예정입니다.
- 기여 방법에는 코드 작성, 토론 참여 등이 있으며, 커뮤니티의 협업을 통해 재현 및 연구 효율성을 높이는 것이 목표입니다.
반응형
'📚 Copy & Paste' 카테고리의 다른 글
| 2025-02-12 Copy & Paste (1) | 2025.02.12 |
|---|---|
| NVIDIA RTX 5060 : 2025년 3월 출시 전망과 예상 스펙 분석 (0) | 2025.02.12 |
| 행복 세트 포인트에 대하여 (3) | 2025.01.16 |
| 1L의 눈물을 읽으며 (0) | 2025.01.15 |
| 2022년 빛 방출량으로 알아보는 대한민국 도시 (1) | 2025.01.13 |

댓글